Playing FPS games using Reinforcement Learning
Playing FPS games using Reinforcement Learning
I like programming, math, machine learning and video games. Reinforcement learning combines all of these. This is a series of posts of our journey in developing some kickass machine learning algorithms with the end goal of crushing Doom2.
Goal
Doom2 is immensely difficult to master so we are starting simple.
- Playing from raw pixel input
- Using autogenerated easy maps and handcrafted maps at first
- Maps that have no enemies
- Maps with consistent theme
- No secrets, teleporters, only exit
- Learning navigation first
I’m using vizdoom, a AI research platform for Doom2 machine learning.
Long term goals
- To learn reinforcement learning and computer vision
- To have fun
- To create an agent that learns novel Doom strategies
- To create an agent that is able to play vanilla Doom2 maps relatively well
Research
There has been research on RL in video game and FPS context for quite a long time. I summarize the relevant parts from my perspective.
If you’re totally new to RL, here are some good starting points:
Key research publications in Deep RL:
- List by OpenAI
- Playing Atari with Deep Reinforcement Learning, Mnih et al, 2013. Algorithm: DQN.
- Asynchronous Methods for Deep Reinforcement Learning, Mnih et al, 2016. Algorithm: A3C.
- DreamerV3
- Muzero and its predecessor of sorts, AlphaZero
Research on Vizdoom platform and related to Doom and FPS games:
- Song et al. have created an environment-aware hierarchical method that uses a manager-worker-model.
- Self-Supervised Policy Adaptation during Deployment
- Combo-Action
- Playtesting: What is Beyond Personas
- Successor Feature Landmarks for Long-Horizon Goal-Conditioned Reinforcement Learning
- DRLViz: Understanding Decisions and Memory in Deep Reinforcement Learning
- Expert-augmented actor-critic for ViZDoom and Montezuma’s Revenge
- Autoencoder-augmented Neuroevolution for Visual Doom Playing
- Clyde: A deep reinforcement learning DOOM playing agent
- Automated Curriculum Learning by Rewarding Temporally Rare Events
- Deep Reinforcement Learning with VizDoom First-Person Shooter
- A Survey of Deep Reinforcement Learning in Video Games
- ViZDoom: DRQN with Prioritized Experience Replay, Double-Q Learning, & Snapshot Ensembling
- Playing FPS Games with Deep Reinforcement Learning
- Learning to Act By Predicting The Future
- Building Generalizable Agents with a Realistic and Right 3D Environment
Other popular methods:
- Deep Deterministic Policy Gradient (DDPG)
- Normalized Advantage Functions (NAF)
- Twin Delayed Deep Deterministic Policy Gradient (TD3)
- Proximal Policy Optimization (PPO)
Approach
The first task: Learn to navigate.
A single frame isn’t enough to deduce the player’s current trajectory, enemy trajectories, let alone remember where the player has came from to the current room and where they should go. Thus, we have to think in terms of sequences of frames.
However, storing long sequences isn’t going to happen. There isn’t enough memory for 35 frames per second and possibly several minutes of gameplay.
There is a way to tackle this though: compress the frames with an autoencoder. A compression ratio of 100-500 is possible to achieve. This means we can fit 100-500 times more frames and thus 100-500 times longer sequences into the GPU memory (regardless of what the baseline is).
NN training on GPUs requires a ton of GPU memory. Not only the input data but also the NN model and the gradients need to fit in the GPU memory during training. You can read more about that here and here.
We plan to push the training limits on a single RTX4090 GPU and then rent a GPU from here for the heavy lifting.
Input
Consider a sequence
\[s = (o_1, a_1, r_1), ..., (o_n, a_n, r_n)\]where \(o\) is the observation, \(a\) action, \(r\) reward for each timestep respectively.
We want to be able to learn the following things:
- a representation of the observation,
e, gotten by autoencoder for example - a dynamics model that learns to predict the next step given current frome and action
- a prediction model that learns the optimal policy and value of the current state
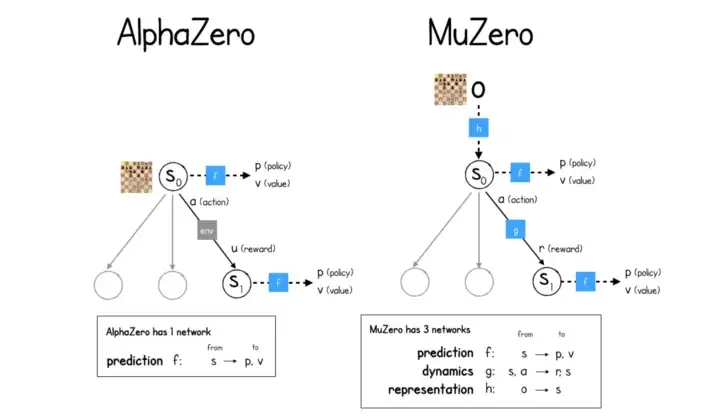
This image from the MuZero algorithm sums it up quite well.
The idea of the agent learning the model dynamics is interesting. It is literally what humans do when they learn new tasks.
The prediction value can be substituted with the Actor-Critic model where there is a model for learning the policy and another for evaluating how good the states attained by the policies are.
We will start with this setting and try to reach small goals one at a time since this task is immensely difficult.
I don’t think a single research team has made an agent that plays real Doom2 levels. If our research project succeeds our model will be able to play Doom, Doom2, Quake, Wolfenstein and literally any FPS game that fulfils certain conditions. I also think that the fact that there are no models that know how to play Doom means it is immensely difficult. However, the recent MineRL models are promising.
This article will continue in the future as follows:
- I will showcase some simple vizdoom cases
- I will test A3C algorithm on them and show the code + results
- The results will be evaluated and future research ideas will be presented
(continued…)